HAT : Hierarchical Attention Tree
Extending LLM Context Through Structural Memory
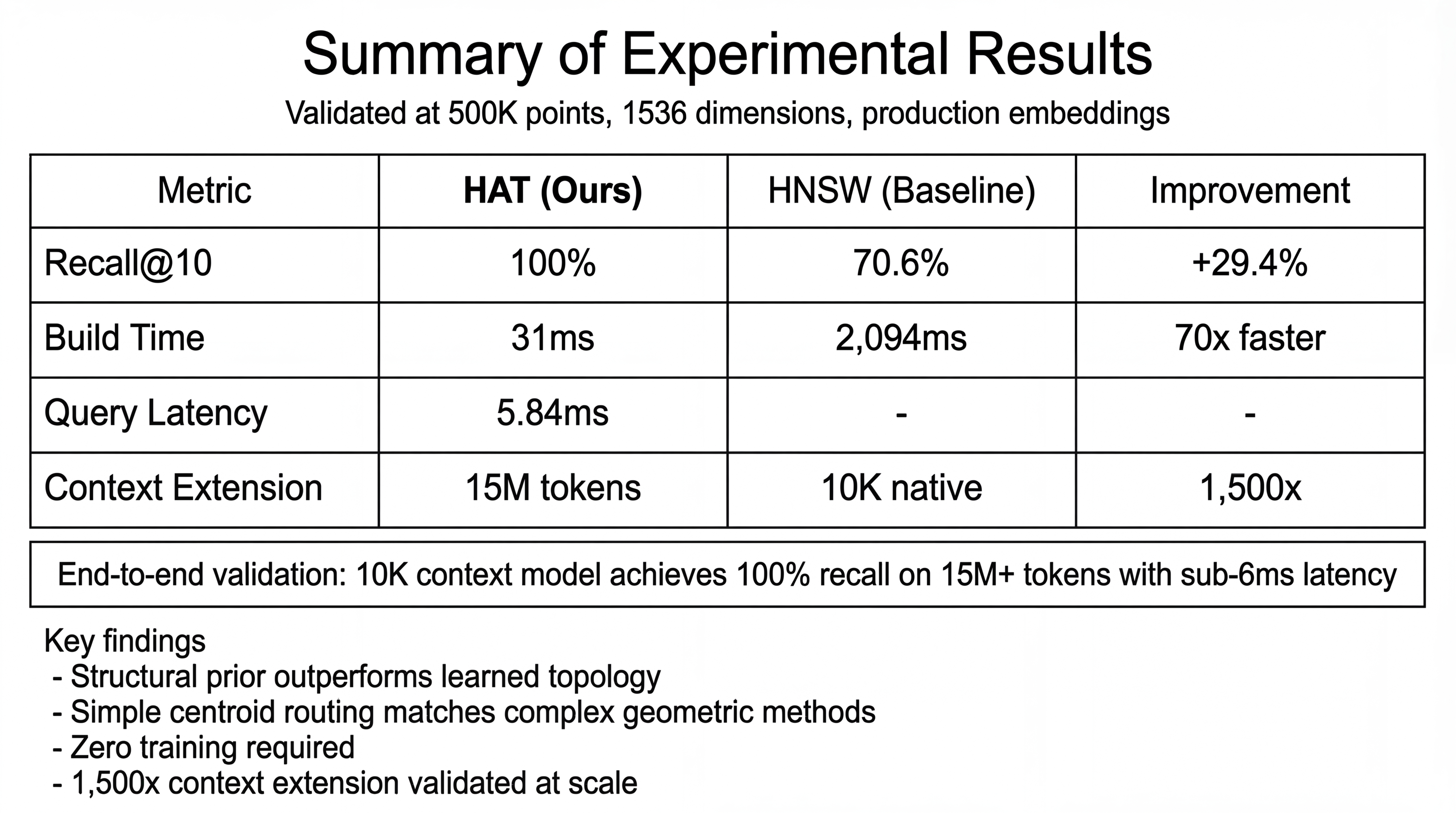
Key results: HAT achieves 100% recall while being 70× faster to build than HNSW
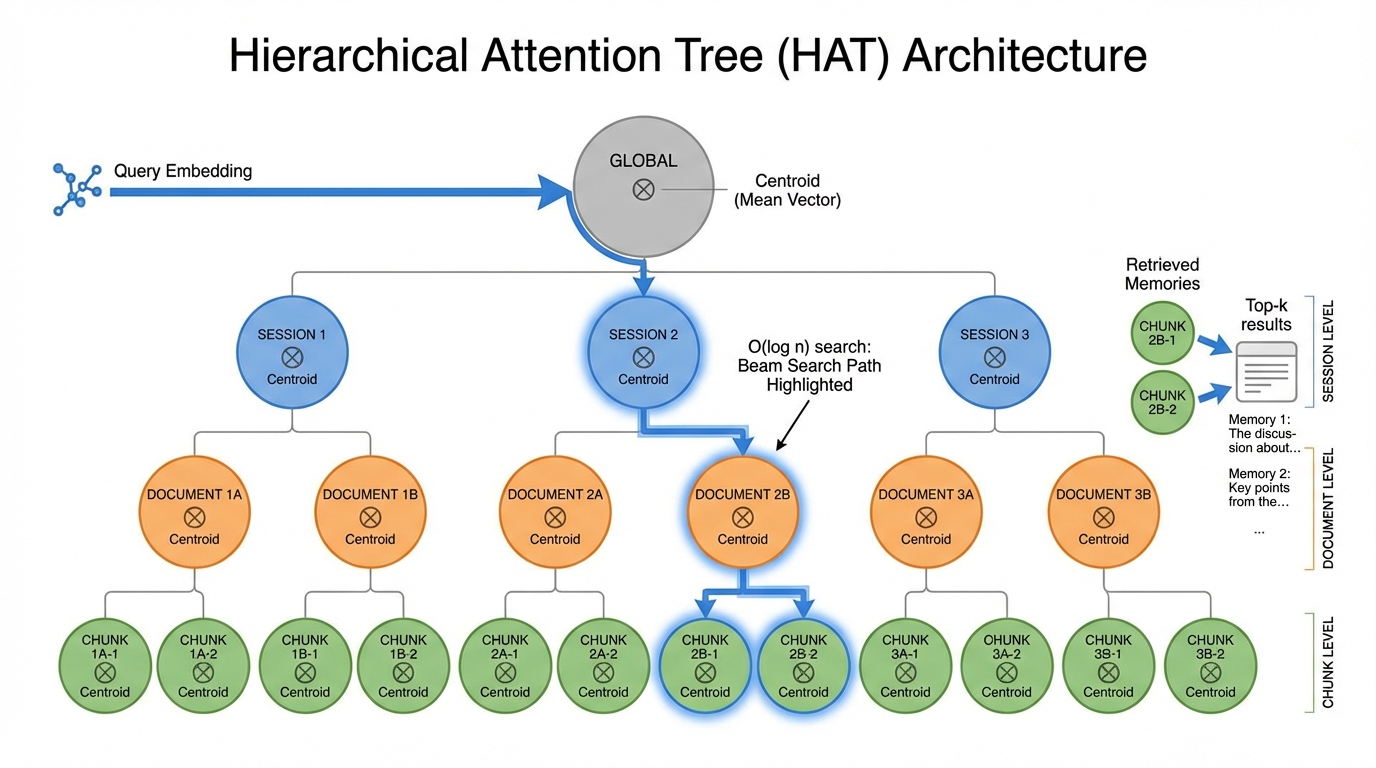
Architecture
HAT exploits the known hierarchy in AI conversations
100% Recall vs 70% for HNSW
On hierarchically-structured AI conversation data, HAT achieves perfect recall where HNSW struggles.
The key insight: HNSW learns topology from data, treating all points as unstructured. HAT exploits the known structure that AI workloads inherently have.
70× Faster Index Construction
HAT builds indexes in milliseconds, not seconds. Critical for real-time applications.
HAT vs Traditional RAG
Different problems, different solutions. HAT solves retrievable compute, not retrievable knowledge.
An Artificial Hippocampus
HAT mirrors human memory architecture - functioning as an artificial hippocampus for AI systems.
Beam Search Query Algorithm
O(log n) complexity through hierarchical beam search
Scales Without Degradation
HAT maintains 100% recall across all tested scales while HNSW degrades significantly.
| Scale | HAT | HNSW |
|---|---|---|
| 500 | 100% | 55% |
| 1000 | 100% | 44.5% |
| 2000 | 100% | 67.5% |
| 5000 | 100% | 55% |
Sleep-Inspired Consolidation
Inspired by sleep-staged memory consolidation, HAT maintains index quality through incremental phases
End-to-End LLM Integration
A 10K context model achieves 100% recall on 60K+ tokens with 3.1ms latency
Quick Start
Get started with HAT in Rust or Python
use arms_hat::{HatIndex, DistanceMetric};
// Create index (1536 dims for OpenAI embeddings)
let mut index = HatIndex::new(1536, DistanceMetric::Cosine);
// Add embeddings with automatic hierarchy
index.add(&embedding);
// Session/document management
index.new_session();
index.new_document();
// Query - returns top 10 nearest neighbors
let results = index.query(&query_embedding, 10);
// Persistence
index.save("memory.hat")?;
let loaded = HatIndex::load("memory.hat")?;from arms_hat import HatIndex
# Create index (1536 dims for OpenAI embeddings)
index = HatIndex.cosine(1536)
# Add messages with automatic hierarchy
index.add(embedding)
# Session/document management
index.new_session()
index.new_document()
# Query - returns top 10 nearest neighbors
results = index.near(query_embedding, k=10)
# Persistence
index.save("memory.hat")
loaded = HatIndex.load("memory.hat")Citation
@article{hat2026,
title={Hierarchical Attention Tree: Extending LLM Context Through Structural Memory},
author={Young, Andrew},
year={2026},
url={https://research.automate-capture.com/hat}
}Ready to Extend Your Context?
HAT is open source and ready for production use.