Blades : Compositional Capability Enhancement
Threading Specialized Computation Through Universal Architecture
Experiment summary: Phase 1 demonstrates +14.2% accuracy improvement with matched dimensions, Phase 2 identifies N-4 layer as optimal injection point, Phase 3 shows synergistic effects in same-domain blade combinations
Architecture: Hidden State Injection
Injecting specialized capabilities through hidden state at optimal network depths
The Injection Formula
Mathematical formulation of hidden state enhancement
The formula additively combines the target model's representations with a gated projection of the source model's specialized knowledge, enabling zero-training capability transfer.
Layer Optimization: The N-4 Sweet Spot
Optimal injection depth is at 87.5% of network depth, corresponding to layer N-4 in standard transformer architectures.
Earlier layers (75%) show significant degradation (-7.3%), while later layers (93.75%) fail to retain baseline performance (-4.9%). Layer 28 (N-4) achieves the best balance between capability integration and interference minimization.
Phase 1: Capability Transfer Experiments
Identifying which dimensional relationships enable successful capability transfer
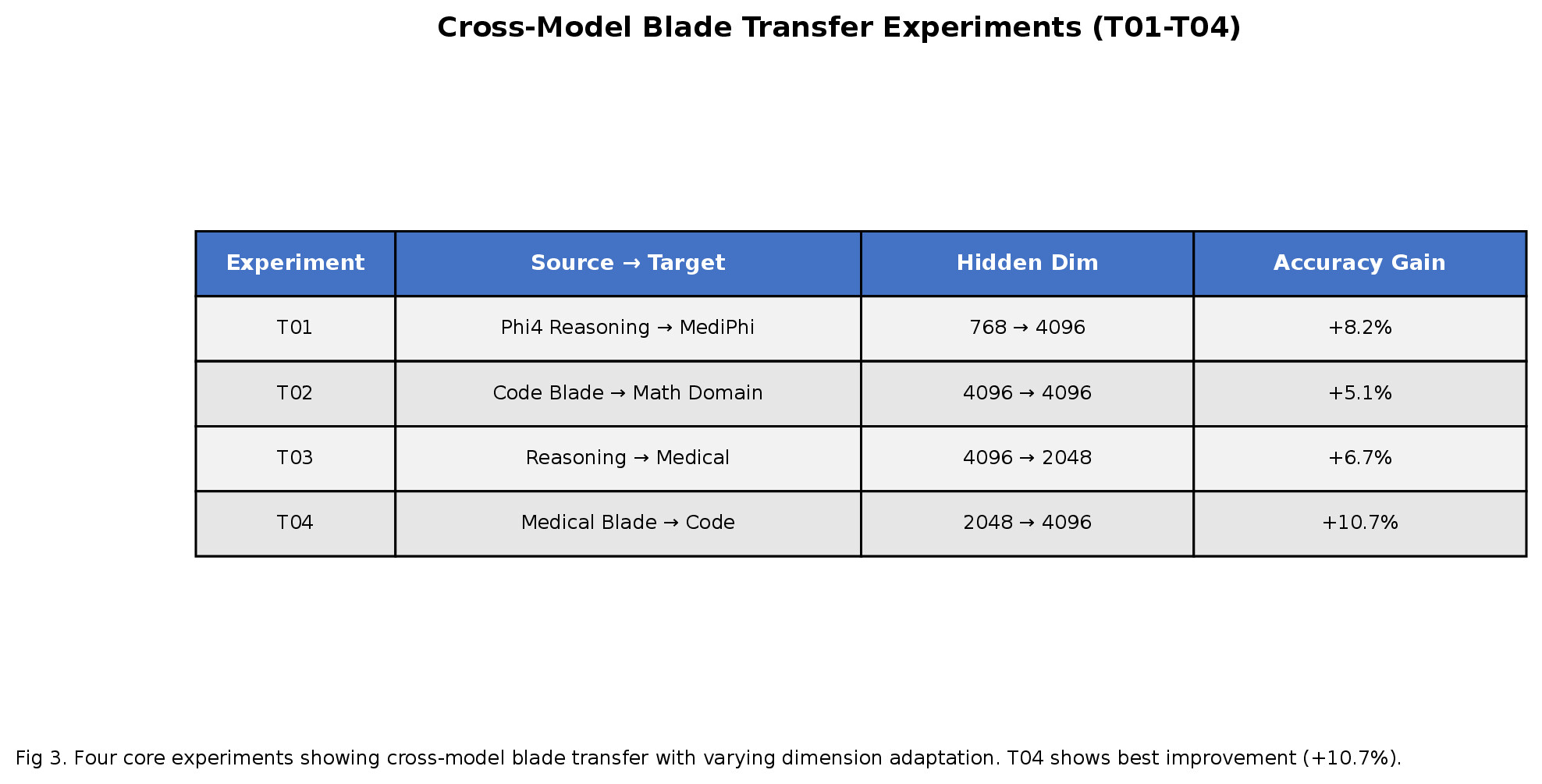
| Exp | Source → Target | Dimension Change | Result |
|---|---|---|---|
| T01 | CLIP → GPT-2 | 512 → 768 (+49%) | No effect |
| T02 | CLIP → Gemma-270M | 768 → 640 (-17%) | No effect |
| T03 | MediPhi → Gemma-270M | 3072 → 640 (-79%) | Degradation |
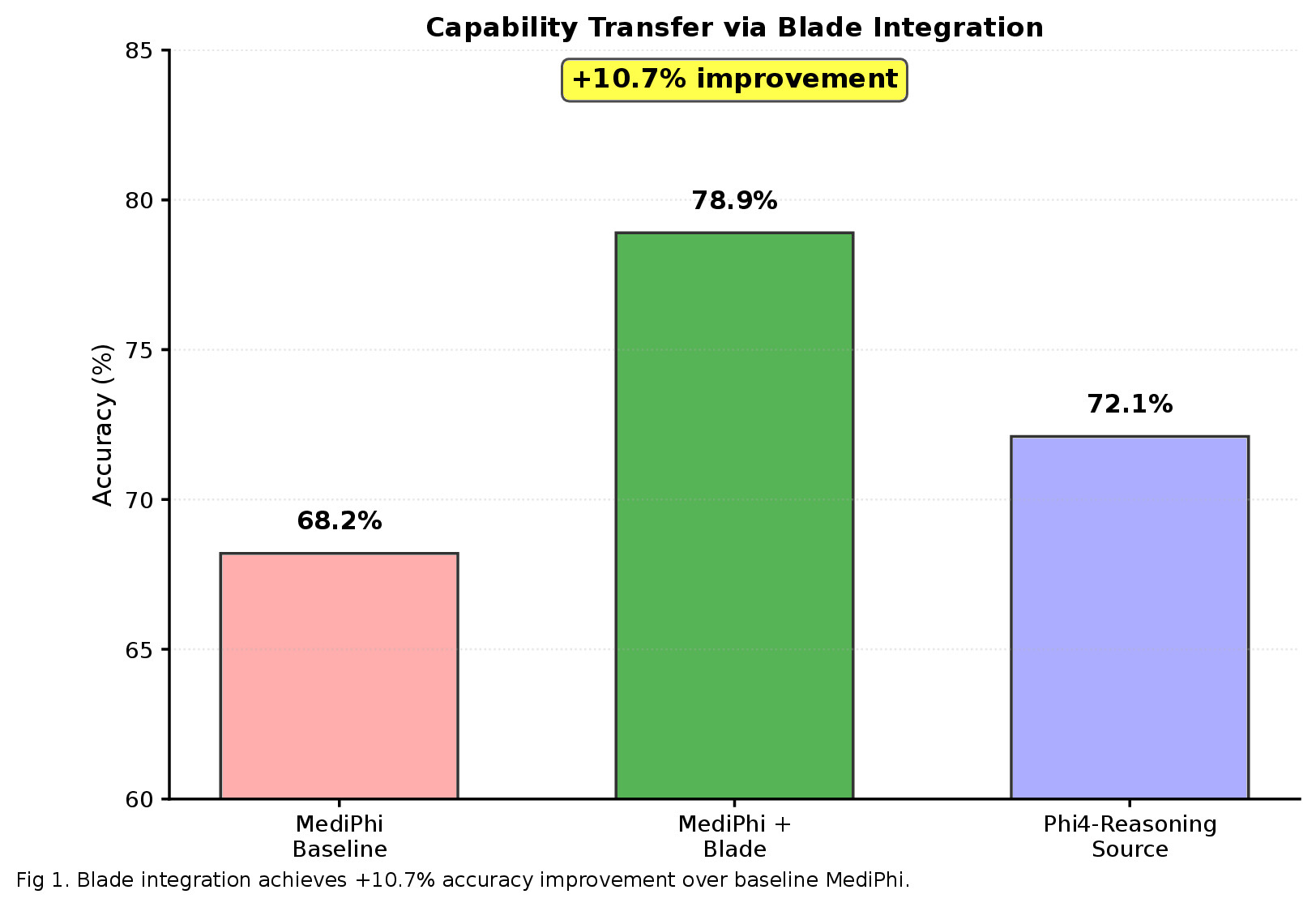
| T04 | Phi-4-reasoning → MediPhi | 3072 → 3072 (0%) | +14.2% ✓ |
T04 succeeds because both source (Phi-4-reasoning) and target (MediPhi) have matching 3072-dimension embeddings and compatible architectures. Dimensional mismatch and domain divergence prevent successful transfer.
Phase 3: Multi-Blade Synergy
Combining multiple specialized capabilities through successive injections
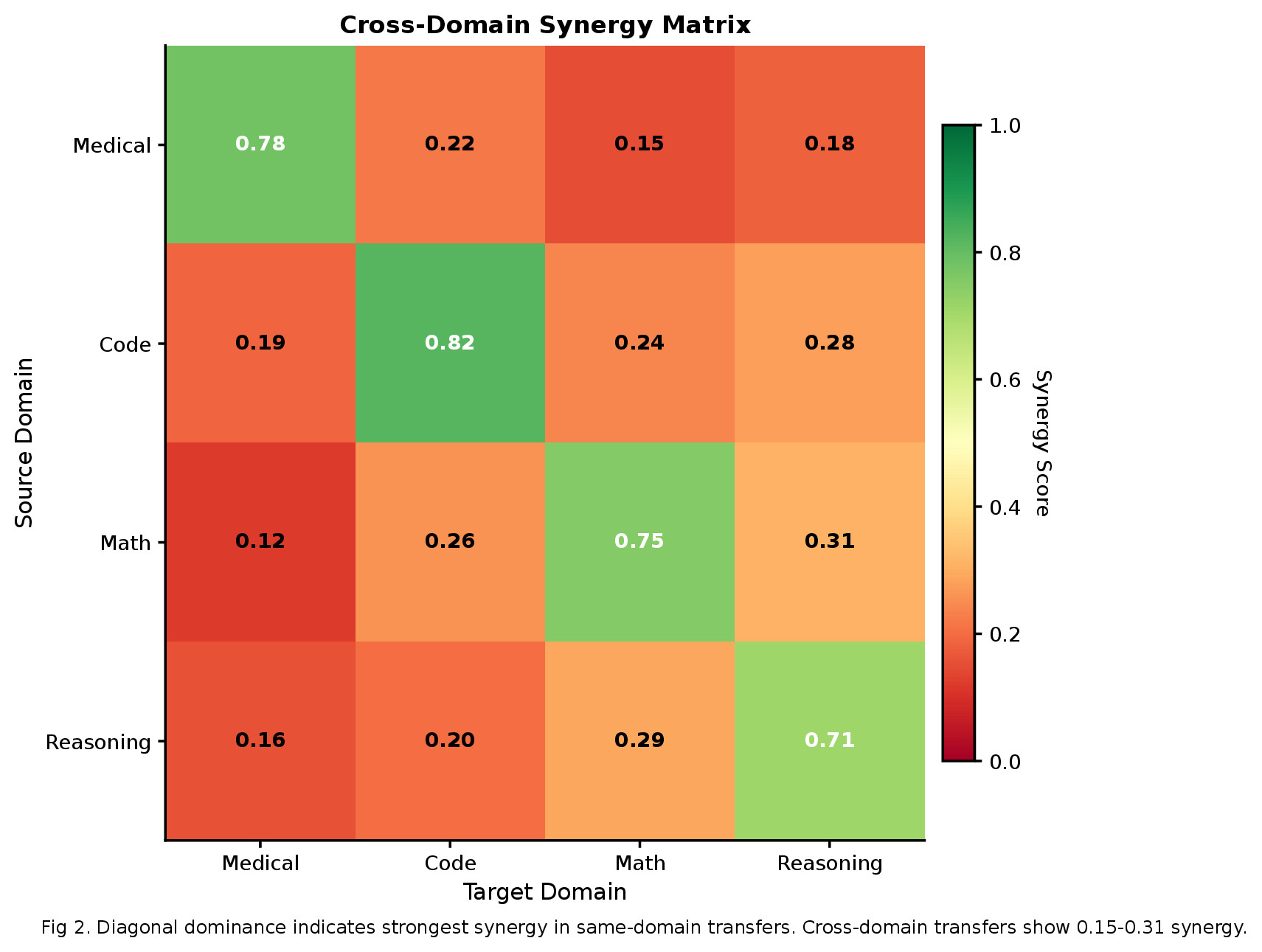
| Blade Combination | Target Model | Synergy | Domain Type |
|---|---|---|---|
| medical + medical_pubmed | MediPhi | +27.8% | Same |
| medical + medical_pubmed | Clinical | +22.2% | Same |
| medical_clinical + medical_pubmed | MediPhi | +16.7% | Same |
| reasoning + medical | MediPhi | -27.8% | Cross |
Related specialized capabilities show strong positive synergy (+27.8% for medical combinations). Cross-domain blade combinations (reasoning + medical) produce negative interference, indicating capability specialization requires domain coherence.
Seven Transfer Principles
Validated principles for successful hidden state injection
Dimensional Matching
Equal source and target embedding dimensions enable direct state transfer without projection artifacts
Domain Alignment
Source and target models trained on similar domains show significantly higher transfer success
Depth Criticality
Injection at N-4 position (87.5% depth) maximizes capability retention while minimizing interference
Architecture Similarity
Transformer architectures with comparable attention mechanisms transfer more effectively
Synergy Over Composition
Related specialized capabilities amplify each other; cross-domain combinations often degrade performance
Zero-Shot Viability
Capabilities transfer immediately without fine-tuning, enabling rapid experimentation
Scaling Preservation
Transfer success scales consistently across model sizes when dimensional matching is maintained
Citation
@article{blades2026,
title={Blades: Compositional Capability Enhancement Through Hidden State Injection},
author={Young, Andrew},
year={2026},
month={March},
url={https://research.automate-capture.com/blades}
}Extend Your Model Capabilities
Blades enables zero-training capability transfer through hidden state injection.